Benchmarks & Evaluation of InfiniteTalk
How InfiniteTalk compares to traditional dubbing and audio-driven I2V models on public datasets—and what that means for real productions.
1. What we benchmark
InfiniteTalk is evaluated on three public datasets that cover both talking-head and full-body motion:
- HDTF – high quality talking-head videos with rich facial dynamics.
- CelebV-HQ – high-resolution celebrity clips with diverse poses, lighting, and styles.
- EMTD – clips with full-body motion, used to test gesture and body–audio synchronization.
We compare InfiniteTalk against two families of baselines:
Traditional dubbing (mouth-only)
- LatentSync
- MuseTalk
Audio-driven image-to-video (I2V)
- FantacyTalking
- Hallo3
- OmniAvatar
- MultiTalk
To evaluate both visuals and synchronization, we track five automatic metrics:
- FID (↓) – per-frame visual quality.
- FVD (↓) – temporal coherence across frames.
- Sync-C (↑) – confidence score for lip–audio synchronization.
- Sync-D (↓) – distance metric for lip sync.
- CSIM (↑) – identity similarity between input and output.
We also run a human study that asks participants to rate lip sync, head & body alignment, identity consistency, and overall naturalness.
2. Traditional dubbing vs sparse-frame dubbing
Traditional dubbing systems like LatentSync and MuseTalk only inpaint a small region around the mouth and keep the rest of the frame unchanged. This tends to:
- Produce very strong FID/FVD scores, because most pixels are copied from the original video.
- Leave head and body motion unchanged, so the performance often feels disconnected from the new audio.
InfiniteTalk instead re-generates the entire frame in an audio-driven way, using sparse keyframes as anchors for identity and camera. This means lips, head, and upper body all move with the dubbed speech.
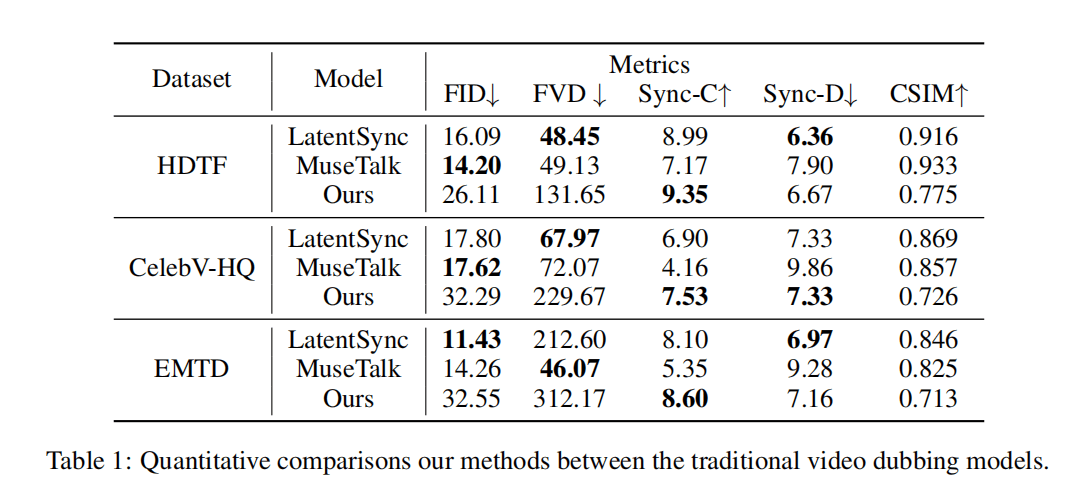
Table 1 · Comparison with traditional mouth-only dubbing models. InfiniteTalk achieves strong lip sync while animating the whole frame.
The key takeaway is that InfiniteTalk trades a small amount of “copy-the-input” FID/FVD for natural, full-frame performances—which is what actually matters for dubbed content.
3. Audio-driven I2V vs InfiniteTalk
Audio-driven image-to-video models like FantacyTalking, Hallo3, OmniAvatar, and MultiTalk start from a single reference image and generate a full video from audio. They perform well on short clips, but for longer sequences they tend to:
- Drift in identity and style.
- Struggle to keep motion and appearance stable over time.
InfiniteTalk focuses on video-to-video dubbing instead of single-image animation. With its streaming architecture, context frames, and sparse keyframes, it:
- Keeps identity and background stable over long sequences.
- Produces strong lip and body sync that follows the dubbed audio.
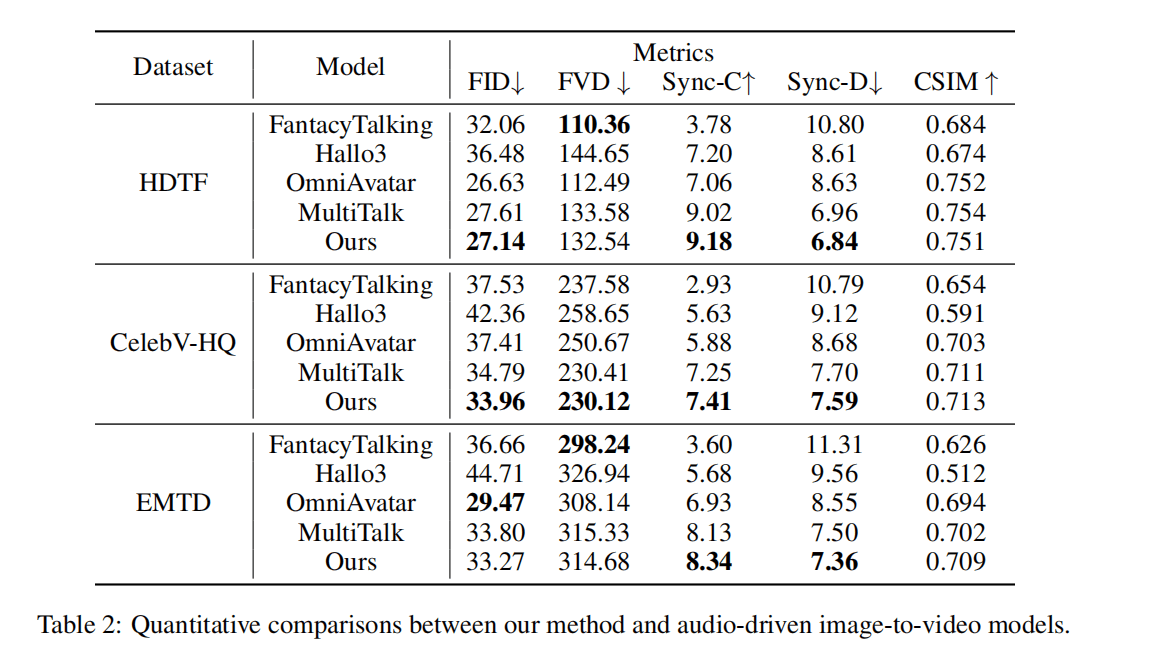
Table 2 · Comparison with audio-driven image-to-video baselines. InfiniteTalk delivers strong lip sync and competitive visual metrics while solving the harder video-to-video dubbing problem.
4. Visual and human evaluation
Numbers only tell part of the story. The paper also presents qualitative comparisons and a human study on the EMTD dataset.

Figure 6 · Visual comparison between traditional mouth-only dubbing and InfiniteTalk. InfiniteTalk animates the whole frame, not just the mouth region.
In the human evaluation:
- Participants ranked methods on lip sync, body sync, identity consistency, and overall naturalness.
- InfiniteTalk achieved the highest average ranking for both lip sync and body motion alignment.
- Mouth-only baselines are limited by the fact that they cannot adjust body motion at all.
For most productions, this means that if you care about how the dubbing feels to watch, full-frame methods like InfiniteTalk are strongly preferred over patch-based edits.
5. Ablation on soft reference control (M0–M3)
Reference sampling matters. The paper evaluates four variants of InfiniteTalk on EMTD, each using a different strategy for placing reference frames in time:
- M0 – same chunk (very strong, local control).
- M1 – first / last frame of each chunk (hard boundary locking).
- M2 – distant chunks (very weak control).
- M3 – neighboring chunks (balanced soft control).
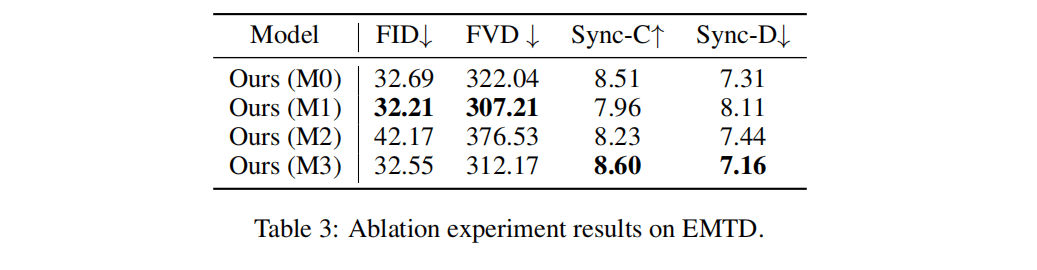
Table 3 · Ablation on reference sampling strategies. M3 offers the best balance between visual stability and lip-sync quality.
In short, M0 and M1 over-constrain motion, M2 under-constrains identity, and M3 provides the best trade-off. That is why M3-like sampling is used as the default soft reference control strategy in InfiniteTalk.
For a deeper conceptual explanation of soft reference control and the M0–M3 strategies, see: /lib/soft-reference-control.
6. Camera control benchmarks
Many real videos include camera motion—slow pans, handheld shake, zoom in/out. The paper investigates how well InfiniteTalk can preserve this when dubbing.
Two plugin-style variants are evaluated on top of InfiniteTalk:
- InfiniteTalk + SDEdit – injects a noisy version of the source trajectory into the generation process, better reproducing subtle camera motion while keeping backgrounds stable.
- InfiniteTalk + Uni3C – adds a ControlNet-like branch for camera motion control; it matches motion but can sometimes distort backgrounds.

Figure 7 · Camera control comparison. Different plugins offer trade-offs between motion fidelity and background preservation.
These experiments inform future product options like “preserve original camera motion” or “stabilize camera,” depending on your content needs.
7. How to interpret these benchmarks as a creator
Putting everything together, you can read the benchmarks like this:
| Dimension | Traditional dubbing(mouth-only) | Audio-driven I2V | InfiniteTalk(sparse-frame) |
|---|---|---|---|
| Lip sync | Good | Good | Best (metrics + human) |
| Head & body alignment | Poor (body never changes) | Medium (short clips) | Best, even on long clips |
| Identity & background stability | Very high (copies input) | Degrades over long sequences | Stable with sparse keyframes |
| Temporal coherence (FVD) | Excellent but trivial (little change) | Good, then drifts | Competitive with full-frame edits |
| Full-frame dubbing | ✗ Mouth only | ✓ Image-to-video | ✓ Video-to-video dubbing |
For your own content, you can think in terms of priorities:
- If you care about natural performances that match the dubbed voice, InfiniteTalk's full-frame, audio-driven approach is what the metrics and human studies support.
- If you care about long-form content like courses, series, or episodes, the streaming architecture and soft reference control are designed specifically for that regime.
- Traditional patch-based edits are still useful when you just need quick mouth fixes, but they cannot replace full-frame dubbing when body language matters.
Want to see how these results connect to the underlying architecture?